CPU '다이'에서는 찍어치기 금지! PC사랑 용어사전
린필드/클락데일의 칩셋 대화 창구 DMI
린필드와 클락데일은 CPU 내부에 메모리 컨트롤러와 그래픽버스를 두어 QPI처럼 외부 장치와 데이터 전송을 담당하는 시스템 버스가 필요 없다. 이들 CPU에는 입출력 버스 컨트롤러(칩셋)와 데이터를 주고받는 DMI(Direct Media Interface)가 채택되었을 뿐이다. DMI는 CPU와 칩셋 사이의 데이터 통로를 가리키므로 FSB나 QPI와는 전혀 다른 개념이다. 참고로 노스브리지와 사우스브리지로 구성된 대부분의 인텔 칩셋은 DMI로 연결되어 있다.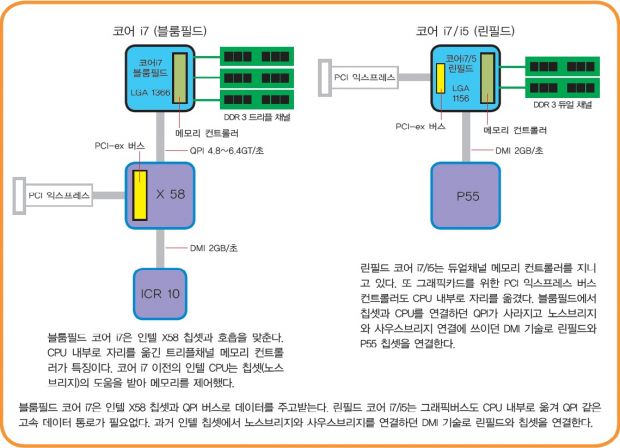
편도 고속도로는 하이퍼트랜스포트가 원조
AMD는 애슬론 64를 도입하면서 일찌감치 단방향 고속 시스템버스인 하이퍼트랜스포트를 도입했다. FSB와 달리 하이퍼트랜스포트나 QPI는 상행선과 하행선이 따로 있는 고속도로의 구조와 같다. FSB는 상하행 구분 없이 차선이 넉넉한 구조다.
하이퍼트랜스포트는 버스의 비트 폭과 신호층 구성에 따라 전송속도를 달리 할 수 있다. 비트 폭을 늘려서 전송속도를 높였던 이전 방식의 시스템버스와 달리 비트 폭을 최대 32비트로 제한하는 대신 작동 속도를 수 GHz까지 높여 데이터 전송속도가 빠르다.
현재 AM3 소켓의 AMD CPU는 하이퍼트랜스포트 3.0 규격을 이용하고 있다. 이 규격은 1초에 최대 40억 차례 데이터를 전송한다. 버스폭은 16비트고 최대 대역폭은 16GB/초다. 
블룸필드와 걸프타운의 데이터 통로 QPI
인텔은 네할렘 설계를 적용한 CPU 시스템에 기존에 쓰던 FSB 대신 QPI라는 새로운 시스템 버스를 적용했다. ‘상호 연결을 위한 빠른 통로’ 정도로 해석할 수 있는 QPI(Quick Path Interconnect)는 종전 FSB로 대표되는 인텔의 시스템 버스의 단점(대역폭 한계 봉착, 낮은 효율 등)을 개선해 데이터 전송 속도가 약 2배까지 빨라졌고, 구조가 단순해 설계는 쉽고 성능 향상은 용이한 것이 특징이다. QPI 버스는 CPU와 메모리, 입출력 컨트롤러(칩셋)을 연결하며, 서버 시스템에서는 2개 이상의 CPU를 직접 연결하는데 쓰이기도 한다.
데이터 전송속도는 4.8GT/초에서 6.4GT/초 사이다. 실제 데이터 버스 클록은 2.4~3.2GHz이고, 버스대역폭은 19.2~25.6GB/초다.
데스크톱 CPU에서 QPI가 적용된 것은 코어 i7 900 시리즈뿐이다. 코어 i7 익스트림 980X에는 6.4GT/초※ 규격의 QPI가 적용되었고, 다른 900 시리즈에는 4.8GT/초의 QPI가 적용되었다.
※1GT/초는 1초에 10억 번 데이터를 전송한다는 뜻이다.
공식 알면 복잡한 계산도 척척 명령어 셋
MMX, SSE 4, AMD 3D나우! 등을 명령어, 또는 명령어 셋이라고 부른다. 자주 다뤄야 하는 일정한 패턴의 연산 과정을 빠르게 처리하기 위한 기능으로, 수학 시험에 빠지지 않고 등장하는 공식과 비슷한 것이라고 생각하면 이해가 쉬울 것이다. 자주 등장하는 데이터 계산의 패턴을 CPU에 넣어두고, 이에 해당하는 작업을 요구하면 공식을 대입해 빠르게 결과는 내는 것이다.
컴퓨팅 환경 흐름에 따라 이러한 명령어는 계속 늘어가는 동시에 변화하고 있다. 물론 이 기능을 제대로 활용하려면 해당 명령어를 써서 연산하도록 프로그램을 설계해야 한다. 명령어는 용도나 쓰임새가 비슷한 것끼리 묶어 추가되는 경우가 많기 때문에 명령어 묶음(set)이라고 부른다. 
SSE3, 3D나우!, MMX 등이 대표적인 명령어 묶음이다. 주로 멀티미디어 처리 속도를 높이는 데 쓰인다.
'잉여'를 적극 활용하는 하이퍼스레딩
인텔이 펜티엄 4 시절에 처음 도입했다. 연산 효율을 높이기 위한 기술로서 하나의 연산 과정이 진행되는 동안 프로세서의 여유 자원에 다른 연산을 끼워 넣는다. 이 기술을 활성화하면 운영체제는 하나의 CPU를 둘로 인식해 동시에 2개의 서로 다른 연산을 처리한다. 하지만 실제 CPU는 하나이고 남는 자원을 활용할 뿐이어서 실제 2개의 CPU를 쓰거나 코어가 2개인 것과는 상당한 성능 차이가 있다.
일정 단위로 진행되는 연산 과정에 필요한 자원과 남는 자원을 정확히 파악하고, 다른 연산 과정을 적절히 끼워 넣는 셈이라서, 실제 성능은 이론상의 효과만큼 크지 않아 펜티엄 4 이후 한동안 쓰지 않다가 네할렘(블룸필드, 린필드, 클락데일) 세대 CPU부터 다시 등장했다. 
하이퍼스레드는 CPU의 여유 자원을 활용해 동시에 복수의 연산 과정(스레드)를 처리하는 기술이다.
쓰지 않을 때는 절전모드로 스피드스텝/쿨앤콰이어트
최근까지 CPU의 작동 속도는 고정되어 있었다. 이용자가 트릭을 써서 강제로 조정하지 않는 이상 항상 제조사가 정한 클록으로 작동했다. 이렇다보니 CPU가 연산을 하지 않을 때도 전력소모가 컸다. 일정 시간 쓰지 않으면 CPU가 작동을 멈추고 대기상태에 들어가기도 하지만 다시 일을 하려면 시간이 필요하기 때문에 이용자가 오랜 시간 자리를 비울 때만 대기상태에 들어가도록 한다.
스피드스텝과 쿨앤콰이어트는 CPU를 완전한 대기상태로 보내는 것이 아니라 전압을 살짝 낮춰 낮은 클록에서 작동하도록 하는 절전기술이다. 이 상태에서 연산 작업이 시작되면 이용자가 느끼지 못한 짧은 시간에 다시 원래 클록으로 작동한다. 노트북 CPU를 위해 개발되었다가 지금은 데스크톱까지 널리 적용되고 있다. 꾸준한 기술 개발로 현재는 이용 상태에 따라 필요한 성능을 제공할 수 있게 클록을 다양하게 조절하고, 클록이 바뀌는 지연시간도 상당히 짧아졌다.
최근 등장한 인텔의 ‘터보부스트’나 AMD의 ‘터보코어’ 기술은 스피드스텝이나 쿨앤콰이어트의 작동 원리를 역으로 활용한 기술이다. 즉 시스템이 높은 성능을 요구할 때 거꾸로 일순간 전압을 올려 작동 클록을 높이는 것이다. 스피드스텝이나 쿨앤콰이어트가 다운클록 기술이라면, 터보부스트나 터보코어는 시스템이 자동으로 오버클록으로 성능을 높이는 기술이다. 
페넘 X4 9850 기본 클록 2,500MHz
쿨앤콰이어트 작동 클록 1,250MHz
반도체를 구성하는 기초 단위 트랜지스터
CPU는 물론이고 그래픽카드의 프로세서, 메모리, 갖가지 컨트롤러 등은 모두 반도체다. 반도체란 일정한 조건에서만 전기가 통하는 물질이다. 보통의 반도체 칩은 수많은 트랜지스터가 모여 하나를 이룬다. 즉, 여러 종류의 프로세서에는 스위치 구실을 하는 수많은 트랜지스터나 일정 조건에 따라 전류를 흘려보내거나 차단해 복잡한 계산을 수행한다. 당연히 스위치가 많을수록 복잡한 연산을 빨리 처리할 수 있다. 물론 수많은 트랜지스터를 제어할 수 있는 기술이 뒷받침되어야 한다.
최근 등장한 첨단 프로세서에는 수십 나노미터 크기의 트랜지스터가 들어간다. 이를 한 줄로 세우면 수천만 개를 모아야 1m가 된다. 사람의 적혈구 위에는 요즘 CPU의 트랜지스터를 수백개 올려놓을 수 있을 정도로 작다. 머지않은 미래에는 분자 크기의 트랜지스터가 쓰일 것으로 보이며, 원자 단위의 트랜지스터 연구도 진행되고 있다.
인텔 코어 i7 980X에는 11억 7000만 개의 트랜지스터가 들어간다. 데스크톱에 들어가는 반도체 중 가장 덩치가 큰 것이 GPU인데, 특히 엔비디아 GTX 480은 무려 30억 개의 트랜지스터로 구성된다.
전통적인 트랜지스터와 동일한 구실을 하는 미세한 회로가 수억개 이상 쌓여서 하나의 프로세서를 이룬다.
CPU 다이에서는 찍어치기 금지!
받침대(臺)를 뜻하는 ‘다이’가 아니라, 네모난 틀의 금형 또는 거푸집을 뜻하는 영어 die다. CPU 윗면의 금속 덮개를 분리하면 손톱보다 작은 유리나 도자기 비슷한 느낌이 나는 손톱보다 작은 사각형 부분이 드러난다. 이것이 바로 CPU의 트랜지스터가 직접된 부분이고 흔히 ‘다이’라고 한다. 이 부분을 제외한 초록색 플라스틱 물질은 전기를 전달하기 위한 기판일 뿐이다. 제조공정(나노미터)이 같다면 다이가 커야 트랜지스터가 많이 집적되었다는 뜻이다. 트랜지스터 숫자가 비슷하더라도 미세 공정에서 만든 CPU일수록 다이가 더 작다. 
다이가 노출된 모바일 CPU. 가운데 유리처럼 보이는 부분이 CPU 다이다. 이곳에 CPU의 모든 회로가 압축되어 있다. 청색 부분은 전기 신호 전달을 위한 배선일 뿐이다.
정리_PC사랑 조정제 bulbup@ilovepc.charislaurencreative.com